
Do you know the feeling when someone gives you a flat file to import, without any schema information? You have to dump it in your database as-is, then spend precious time figuring out the data type for each column 😥
Let me help you with that, as I’m helping myself too.
Use case:
- Someone sends you a flat file (csv), of course they don’t give you ANY information about the data types contained in it
- You dump it as-is in your database staging area:
- When using SSMS Flat file importer it can mostly do this job for you, but not 100%
- But if you’re like me and get files from a Data Lake and import it straight away with Azure Data Factory with the “just auto create the table and I’ll deal with it later because I can’t bother right now please” flag on you end up with a table with the right column names but all nvarchar(MAX) columns because the import engine is as lazy as me
- At the end of the day you have this table with sub-optimal data types, and here is where this dumb script can help you
Using the power of trial and error and dynamic SQL, I’ve come up with this script which basic idea is simply doing a TRY_CONVERT in various data types (most common defined, you can add more and/or different sizes easily) and checking if the engine was able to convert all of them: it comes up with suggestions about compatible file types for each column, the min/max length for any varchar value and a useful raw data sample too 😉
Here is a sample output:
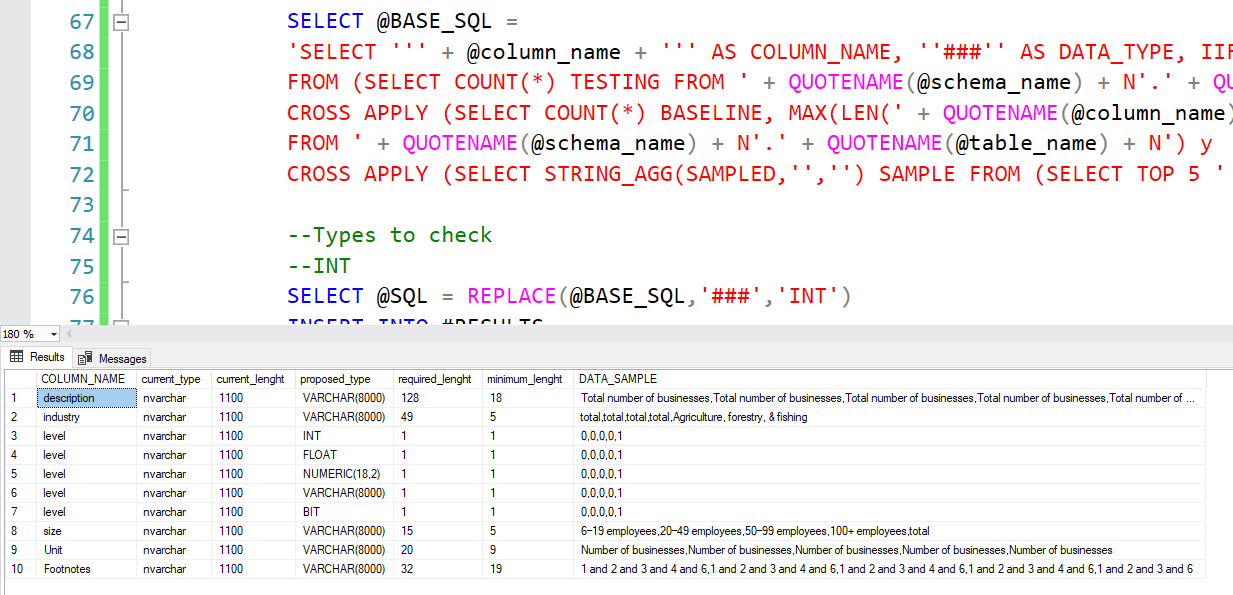
Of course this is a first draft that can be expanded upon, but that’s what open source is all about, you can do it yourself 👀
Find the full script on my GitHub: tsql.tech-Code-snippets/Schema-Related/data column type checker+suggester.sql at master · EmanueleMeazzo/tsql.tech-Code-snippets (github.com)
You’re welcome.