
I was reading Paul White’s post about bitmaps in SQL Server and, other than realizing that I basically know nothing about anything (like a Socrate’s epiphany) I wanted to at least see how this good stuff added up in the latest 7 years.
Down with experimenting, we’re doing this LIVE! (Well, it’s live for me, for you it’s still a blog post)
I’ll start by creating two BigInt-only tables and fill it a bunch of numbers, one small and one big, leaving them as heaps for now
CREATE TABLE #TSmall
(
ID bigint not null
);
CREATE TABLE #TLarge
(
ID bigint not null
);
CREATE TABLE #ADD_BATCH_MODE (I INT, INDEX CCI CLUSTERED COLUMNSTORE);
WITH Tally (N) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns a CROSS JOIN sys.all_columns b
)
SELECT TOP 500000000 N
INTO #Numbers
FROM Tally;
INSERT INTO #TSmall
SELECT N
FROM #Numbers
WHERE N % 15 = 0
INSERT INTO #TLarge
SELECT N
FROM #Numbers
Everybody’s thing to do first: Take baseline measurements, I’ll always indicate the CPU and Execution times of the queries as a comment in the code, to better associate each query to its time
SET STATISTICS TIME ON; SELECT COUNT(*) FROM #TSmall S JOIN #TLarge L ON S.ID = L.ID OPTION (MAXDOP 1); --CPU time = 12891 ms, elapsed time = 13306 ms. SELECT COUNT(*) FROM #TSmall S JOIN #TLarge L ON S.ID = L.ID; --CPU time = 11966 ms, elapsed time = 1819 ms.
As expected the multi-threaded query is faster because it was able to create and use a Bitmap:
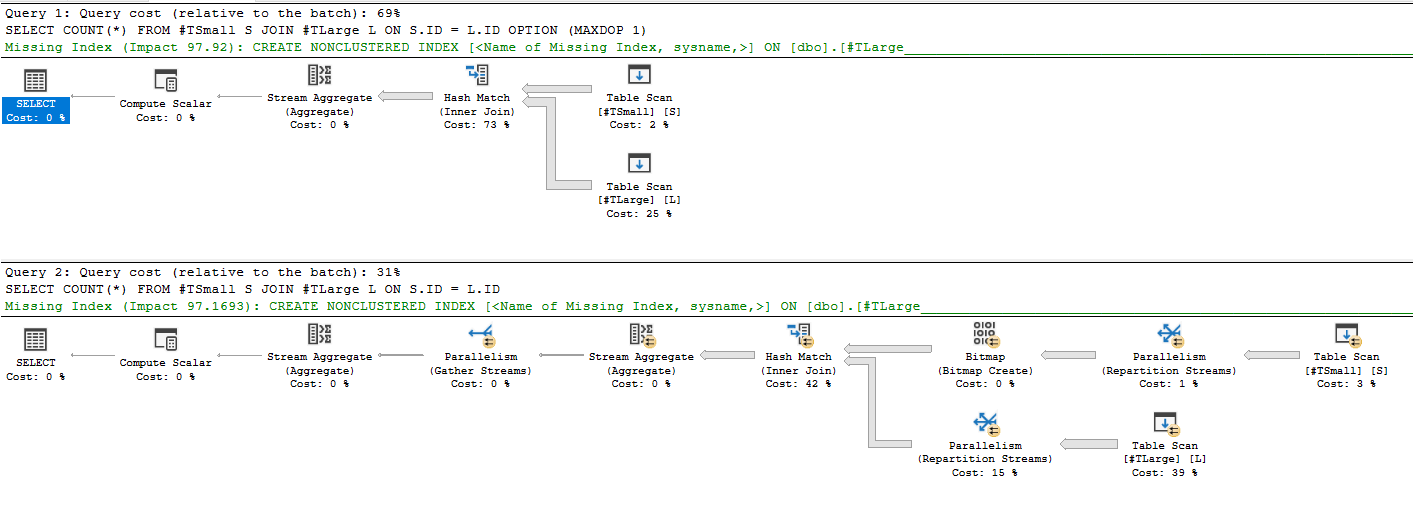
Focusing on the probe-side Scan operator (Scan on #TLarge) i notice the following:
Interesting takeaways:
- The bitmap probe has been pushed down to the storage engine as an “IN ROW” predicate, meaning that the filter is pushed into the Storage Engine, and applied to rows as they are being read.
- Indeed the operator read all the rows in the scan operation but only the relevant ones were sent to the Hash Match operator
- We haven’t seeked on anything (since there are no indexes at the moment) but were able to work on a subset of data regardless, massively speeding up the query
I wonder what happens if I add some indexes?
CREATE UNIQUE CLUSTERED INDEX cx_S on #TSmall (ID); CREATE UNIQUE CLUSTERED INDEX cx_L on #TLarge (ID); GO SELECT COUNT(*) FROM #TSmall S JOIN #TLarge L ON S.ID = L.ID OPTION (MAXDOP 1); --CPU time = 5828 ms, elapsed time = 5860 ms. SELECT COUNT(*) FROM #TSmall S JOIN #TLarge L ON S.ID = L.ID; --CPU time = 8266 ms, elapsed time = 1328 ms.
Times went down for both queries but for different reasons, the biggest improvement was made on the serial query, let’s see why:

The serial query made the big jump in performance because it switched to a Merge Join, which was able to stream the rows of both tables at the same time:

It was able to skip a bunch of rows at the end when it realized that there couldn’t be any more matching rows from the 1st table but that’s it.
The improvement on the parallel plan is sneakier, as the plan seems exactly the same at first, so how are we able to run even faster?
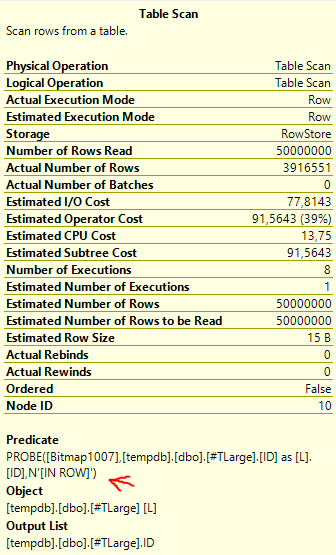
Let’s look at the same scan operator as before:
We still aren’t seeking, but we still haven’t read all the rows, it’s 🌈MAGIC, even better, the magic of predicate pushdowns: In this case having an index on the column allowed to apply the bitmap filter even before the streaming of each row from memory, filtering out the pages that wouldn’t have contained a possibly matching row.
After a brief pause of amazement, let’s ask ourselves: can executing this in batch mode be even faster‽
Let’s try with a batch mode trick:
--This is a neat trick to enable batch mode on rowstore indexes CREATE TABLE #ADD_BATCH_MODE (I INT, INDEX CCI CLUSTERED COLUMNSTORE); GO SELECT COUNT(*) FROM #TSmall S LEFT OUTER JOIN #ADD_BATCH_MODE ON 1=0 JOIN #TLarge L ON S.ID = L.ID; --CPU time = 13016 ms, elapsed time = 2236 ms.
in this way we’ll only trick the optimized into using the batch mode where it can in out plain rowstore indexes, we get an interesting picture from here:
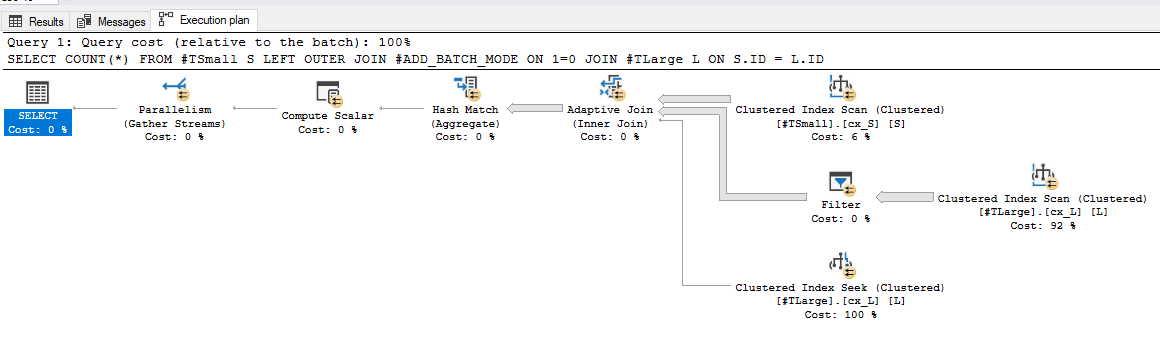
BEHOLD the Adaptive Join operator! But of course in the end it chose the Hash Match join, because we already know that we had too may rows for an inner loop join, but for some reason the optimizer didn’t consider the information that it already had before, weird.
A bitmap is created regardless, but isn’t shown in the plan: it’s used a predicate for the filter operator.
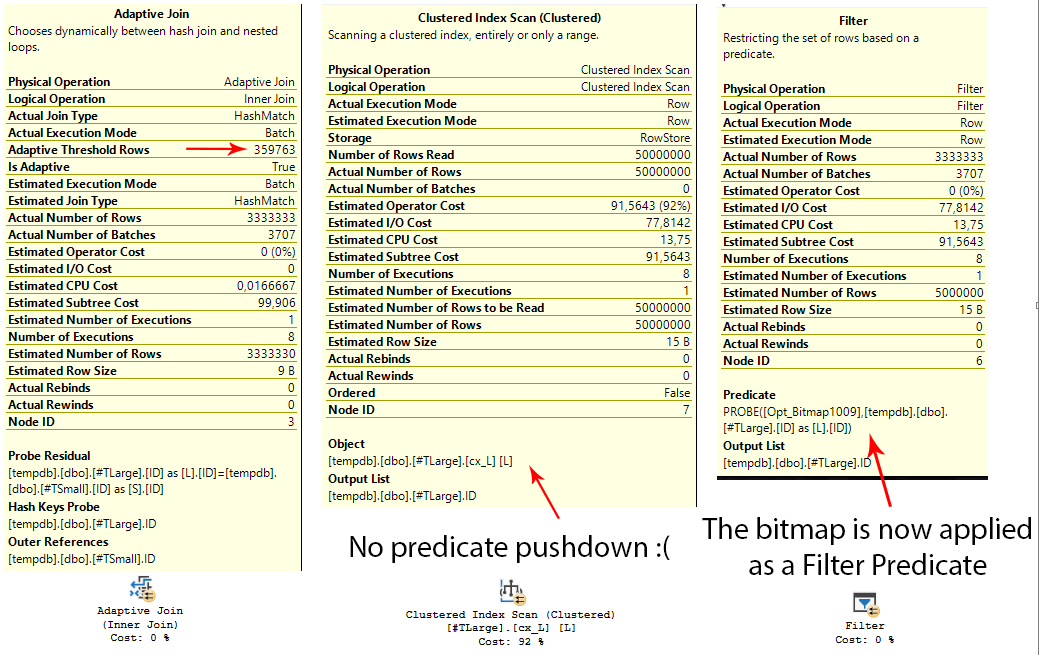
So, we switched to a batch mode join, which is super fast, but which is really only the residual probe of the Filter operator that was inserted in the new plan, and the scan needs to read all the rows in the table, regardless.
The timing is good, but it’s worse than the plain parallel plan, leaving us with a “meh”.
What if we put everything in Columnstore Indexes?
CREATE CLUSTERED COLUMNSTORE INDEX cx_S on #TSmall WITH (DROP_EXISTING = ON) CREATE CLUSTERED COLUMNSTORE INDEX cx_L on #TLarge WITH (DROP_EXISTING = ON) GO SELECT COUNT(*) FROM #TSmall S JOIN #TLarge L ON S.ID = L.ID OPTION (MAXDOP 1); --CPU time = 578 ms, elapsed time = 589 ms. SELECT COUNT(*) FROM #TSmall S JOIN #TLarge L ON S.ID = L.ID; --578 ms, elapsed time = 591 ms.
(MAXDOP 1) is basically useless since the query won’t even need to go parallel, the plans created are the same:
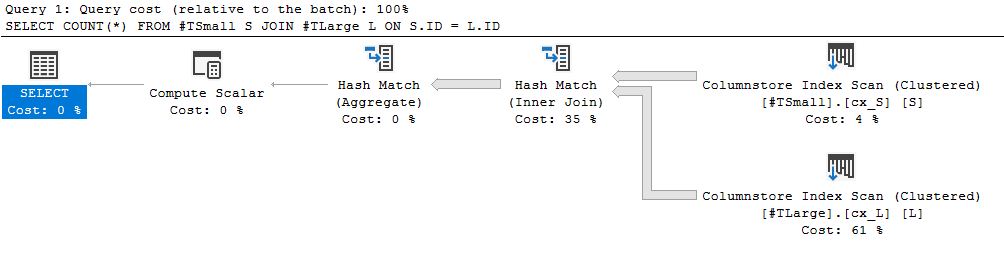
So simple, yet so powerful: Between compression and batch mode execution, the columstore approach smokes even the bitmap pushdown to row in rowstore indexes (and that’s because the index is both smaller in memory and can be scanned in batch mode)

In this plan too, a bitmap is created and used as predicate for the scan operator, which of course runs in batch mode.
We aren’t even skipping segments, since the small table is a linear subset of the large one, so there are no gaps; In a situation where gaps exist, an even faster execution would occur for the columnstore index (while nothing would change for rowstore)
It seems that for these type of queries the columnstore technology can’t be beaten!